Hidesense för databaser
FÖR DATAHÄLSAN
Varför behövs databastvättar?
I datalagringsdirektivet är reglerna hårda för när produktionsdata får användas i teständamål och en organisation kan få kraftiga böter (reglerade som en procent av omsättningen) om de bryter mot direktivet. Grundregeln är att personuppgifter inte får användas i teständamål. Många organisationer gör detta idag på grund av att de testar ett system som ska vara så produktionslikt som möjligt, men genererat testdata har inte samma entropi som riktigt data vilket gör behovet av verklighetsliknande testdata mycket stort.
Lösningen är då att tvätta databasen: exportera produktionsdatabasen som en databasdump, identifiera tabeller och fält som ska tvättas, skriv en konfigurationsfil, tvätta tabellerna och läs in i testmiljön.
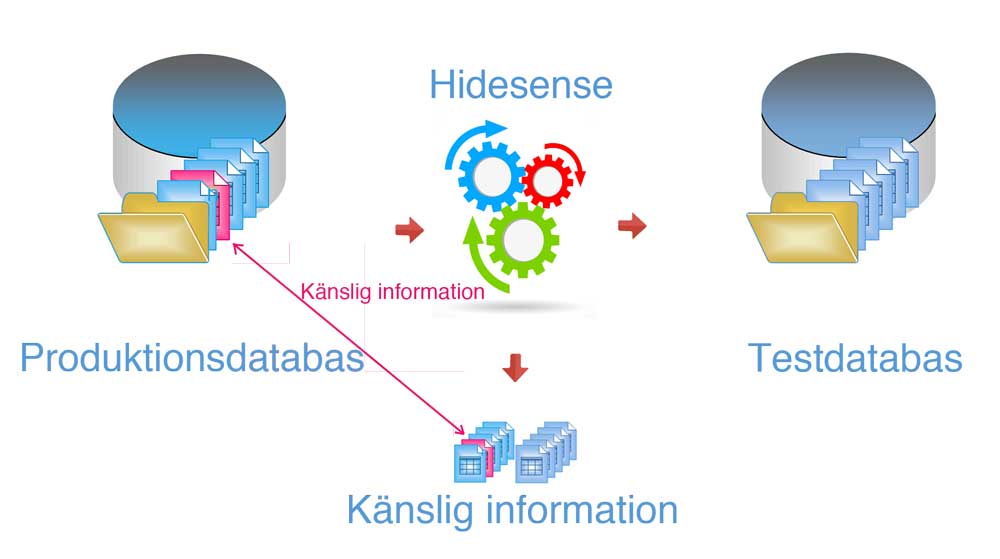
TVÄTT AV EN DATABAS
Att tvätta en databas från personuppgifter.
Det du kommer att behöva är:
- Databasdump. Här används MySql employee-databas, som kan hämtas från https://launchpad.net/test-db/+download
- employees_db-full-1.0.6.tar.bz2
- Möjlighet att packa upp tar och bz2. I OSX finns detta inbyggt.
- MySQL. Här används en MySql på RHEL 6.4
- hidesense-core.jar
- Fil med förnamn: fname.txt
- Fil med efternamn: ename.txt
- Java 1.8.0 eller senare.
STEG 1
Packa upp databasen
Packa upp samtliga filer i en katalog. Öppna ett kommandofönster i den katalogen. Verifiera att databasen inte är installerad.
-u root -p
show databases;
+——————–+
| Database |
+——————–+
| information_schema |
| Syslog |
| mysql |
+——————–+
3 rows in set (0.00 sec)
mysql> exit
Bye
#
I katalogen där databasen är uppackad, kör följande kommando:
-u root -p -t < employees.sq
Databasen ska nu visas. Verifiera att databasen är installerad.
-u root -p
(Ange lösenord för root-användaren på mysql)
show databases;
+——————–+
| Database |
+——————–+
| information_schema |
| Syslog |
| employees |
| mysql |
+——————–+
4 rows in set (0.00 sec)
Notera att databasen employees finns.
use employees
Database changed
show tables;
+———————+
| Tables_in_employees |
+———————+
| departments |
| dept_emp |
| dept_manager |
| employees |
| salaries |
| titles |
+———————+
6 rows in set (0.00 sec)
Visa användartabellen:
select * from employees limit 10;
+——–+————+————+———–+——–+———–+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+——–+————+————+———–+——–+————+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 |
| 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 |
| 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10007 | 1957-05-23 | Tzvetan | Zielinski | F | 1989-02-10 |
| 10008 | 1958-02-19 | Saniya | Kalloufi | M | 1994-09-15 |
| 10009 | 1952-04-19 | Sumant | Peac | F | 1985-02-18 |
| 10010 | 1963-06-01 | Duangkaew | Piveteau | F | 1989-08-24 |
+——–+————+————+———–+——–+————+
10 rows in set (0.00 sec)
Vi ska anonymisera användartabellen och visa den nya efter datatvätten. Ta bort databasen först.
drop table employees;
exit
STEG 2
Skapa översättningsfil
Gå till katalogen där hidesense-core är installerat. Kopiera filen load_employees.dump till den katalogen. Skapa översättningsfilen med följande innehåll:
{
"rules": [
{
"name": "Empoyees-lastName",
"fieldSeparator": ",",
"terminatedBy": ";",
"start": " VALUES",
"groupStop": ")",
"end": ";",
"groupStart": "(",
"groupSeparator": ",",
"mandatory": "INSERT INTO `employees`",
"quotation": "'",
"escape": "\\",
"compoundLinesBytesLimit": "100000",
"fieldNumber": "4",
"to": "${value}",
"type": "DbColumnSubstituter",
"substituter": {
"name": "LIST LASTNAMES",
"from": "'(.*)'",
"groupNumber": "1",
"to": "${value}",
"file": "files\\enamn.txt",
"type": "ListSubstituter"
}
},
{
"name": "Empoyees-firtsName",
"fieldSeparator": ",",
"terminatedBy": ";",
"start": " VALUES",
"groupStop": ")",
"end": ";",
"groupStart": "(",
"groupSeparator": ",",
"mandatory": "INSERT INTO `employees`",
"quotation": "'",
"escape": "\\",
"compoundLinesBytesLimit": "100000",
"fieldNumber": "3",
"to": "${value}",
"type": "DbColumnSubstituter",
"substituter": {
"name": "LIST FIRSTNAMES",
"from": "'(.*)'",
"groupNumber": "1",
"to": "${value}",
"file": "files\\fnamn.txt",
"type": "ListSubstituter"
}
},
{
"name": "Employees-birthDate",
"fieldSeparator": ",",
"terminatedBy": ";",
"start": " VALUES",
"groupStop": ")",
"end": ";",
"groupStart": "(",
"groupSeparator": ",",
"mandatory": "INSERT INTO `employees`",
"quotation": "'",
"escape": "\\",
"compoundLinesBytesLimit": "100000",
"fieldNumber": "2",
"to": "${value}",
"type": "DbColumnSubstituter",
"substituter": {
"name": "Datum",
"stopOnNoSubstitution": "false",
"unique": "false",
"valueNotEqualToKey": "false",
"surrounding": "(\\D|^)${from}(\\D|$)",
"format": "yyyy-MM-dd",
"random.high": "200",
"random.low": "-100",
"from": "\\d{4}-(0|1)\\d-[0-3]\\d",
"type": "DateSubstituter"
}
}
]
}
Notera att files/fnamn.txt och files/enamn.txt måste finnas och innehålla förnamn respektive efternamn. Ett namn per rad. Spara översättningsfilen med namn employees.properties. Kör översättningen genom följande kommando.
$ java -jar hidesense-core.jar -c employees.properties -n db load_employees.dump
Undersök den filtrerade dump-filen så att den inte innehåller några namn. Den översatta filen sparas nu under logs/oppen/load_employees.filtered.dump. Spara original-filen load_employees.dump cd till katalogen där dump-filerna finns.
mv load_employees.dump load_employees.dump.original
cp ……../logs/oppen/load_employees.filtered.dump load_employees.dump
STEG 3
Läs in den tvättade batabasen.
Följ anvisningarna för att packa upp databasen igen. Databasen ska nu inte innehålla några namn.
select * from employees limit 10;
+——–+————+————+———–+——–+————+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+——–+————+————+———–+——–+————+
| 10001 | 1953-08-30 | Bergström | Per | M | 1986-04-20 |
| 10002 | 1964-03-04 | Falk | Irene | F | 1985-10-04 |
| 10003 | 1959-09-11 | Berglund | Therese | M | 1986-08-09 |
| 10004 | 1954-06-30 | Sandberg | Inga | M | 1987-06-18 |
| 10005 | 1954-11-29 | Hermansson | Elisabeth | M | 1989-11-28 |
| 10006 | 1953-06-25 | Lundberg | Lisbeth | F | 1989-04-26 |
| 10007 | 1957-10-17 | Holmqvist | Ulrika | F | 1989-06-25 |
| 10008 | 1958-08-09 | Wikström | Martin | M | 1995-02-19 |
| 10009 | 1952-08-11 | Wallin | Christian | F | 1985-03-16 |
| 10010 | 1963-12-09 | Lindholm | Ingvar | F | 1990-01-02 |
+——–+————+————+———–+——–+————+
10 rows in set (0.00 sec)
Notera att födelsedatum och anställningsdatum är något förändrade (inom ett knappt år) samt att för- och efternamn är helt nya. Vi har inte tagit hänsyn till kön och namn i det här exemplet men det går naturligtvis att göra med andra regler.